Efficiently Obtaining Large Amounts of Data from External APIs with Python
Optimizing Python API Interactions for High-Volume Data

I am a software and data engineer focusing serverless data-intensive applications that are hosted on AWS.
For some analytics or machine learning use cases, you could be dependent on data from external systems. Sometimes, these external systems offer a REST API to query those data. These APIs are usually not designed for large data transfers, which poses challenges in case you need to gather enough data for your ML use case.
In this blog post, I describe how my Python library can be used to make the process of fetching large amounts of data from an API more efficient and fault-tolerant. The source code is in this GitHub repository.
Obtaining large amounts of data from an API can be challenging
In case you need to fetch years of data from many IoT devices, you can imagine that this will take a while. Upon your API query, the backend behind the API needs to get the data from the storage, on which you have no control. Hence, this could be a non-optimized system that will take a long time to return your data. The external systems could even give up, with the API responding with 503 or 504 HTTP status codes. Besides, the data has to travel over networks. Therefore we could face issues related to latency, bandwidth limitations, or packet loss.
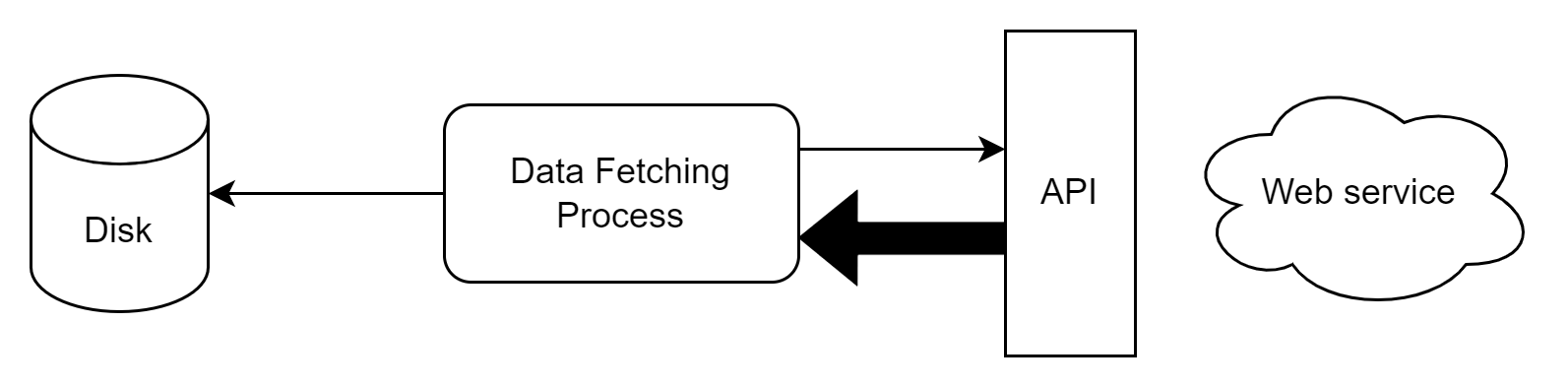
Our goal is to fetch that external data and store it in a system in our control. This is schematically represented in the image below. We assume for the remainder of this blog post, that the most costly step in this process is the interaction with the external API.
Breaking up the work into smaller parts
REST APIs are typically not well-suited for large data transfers from server to client. What often happens is that you can specify the number of samples per page, and then fetch a single page per API request. This splits up the total amount of data into smaller parts and makes handling large volumes of data feasible.
The next question then becomes whether to first fetch all the data and then write it all as a single operation (A), or write a single page of data and write that page right away to disk (B). The picture below gives a schematic overview of both options.
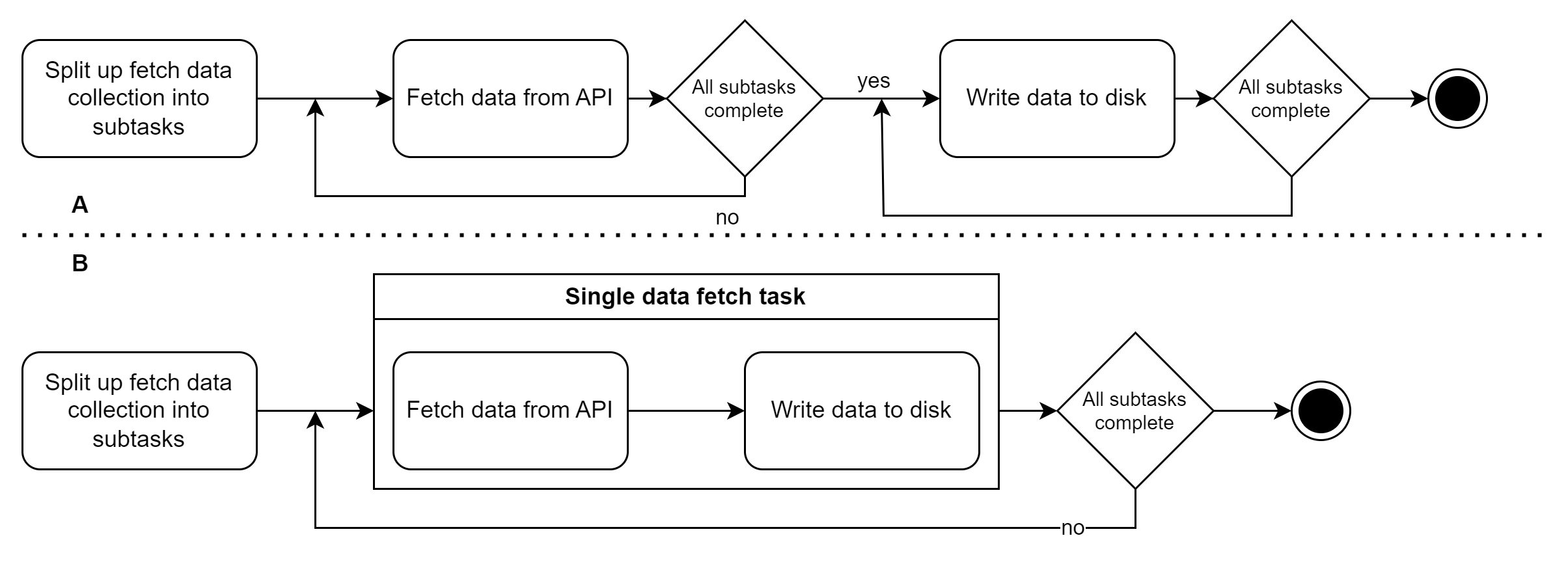
Both options have pros and cons, summarized in the table below. It's up to you to analyze which task should be prioritized for; the data fetching or the writing to disk.
In my case, the data fetching task was the slow (and hence costly) part of my workload. Hence I chose to implement option B (Fetch and write per page).
| Option | Fetched data is lost | Memory usage | Writing to disk |
| Fetch all, then write | Higher chance, high volume | High | Allows for optimization |
| Fetch and write per page | Lower chance, low volume | Low | High overhead for columnar file formats |
Parallelize the work
If we would naively implement the work to be all conducted in series, a big data fetching job will take a long time. All work of the web service behind the API will be done consecutively before a new operation is started. The same applies to the write operations. These IO tasks are going to take up most of the run time of the job, especially if we do not execute any of the work in parallel.
In Python, there are broadly two ways to achieve parallelization: multi-threading and multi-processing. However, we need to take into account Python's GIL (Global Interpreter Lock). The presence of the GIL means that a single process can only execute Python Bytecode from a single thread at a time. This means that for CPU-bound workloads, multi-threading leads to no improvement in run time. In that case, the Python code is performing most of the work that needs to be conducted. However, in the workload at hand, the IO operations (conducted by the Operating System) are the biggest part of the work. Hence, we consider our workload to be IO-bound. The Python interpreter will switch to another thread when it encounters an IO operation on the current thread. In this way, IO work can be executed in parallel, while the Python interpreter only executes a single task. Hereby, we speed up the processing of the work.
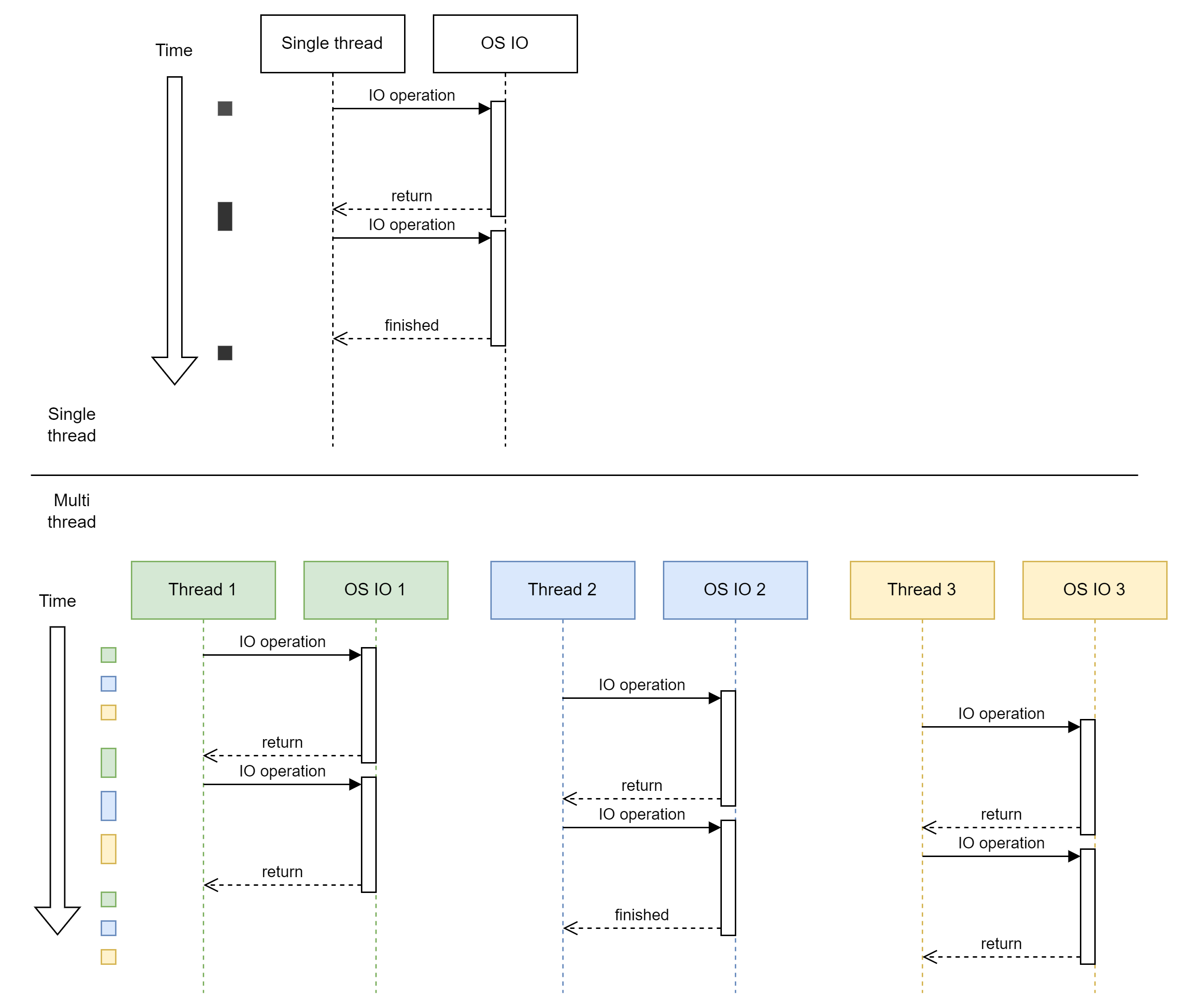
This is visualized in the figure above. The single-threaded solution (top) has much more idle time for the Python interpreter compared to the multi-threaded solution (bottom). Therefore, we can increase the number of IO operations that we can complete per time unit if we run them on multiple threads.
Fetching the external data with multi-threading
For the implementation of everything described below, check out my public data fetch optimization repo. The repo also contains an explanation of how to use the interfaces and classes, rather than a functional overview given in this blog post.
Now I know how we are going to approach the problem and use multi-threading to speed it up, let's make an overview of the entire process.
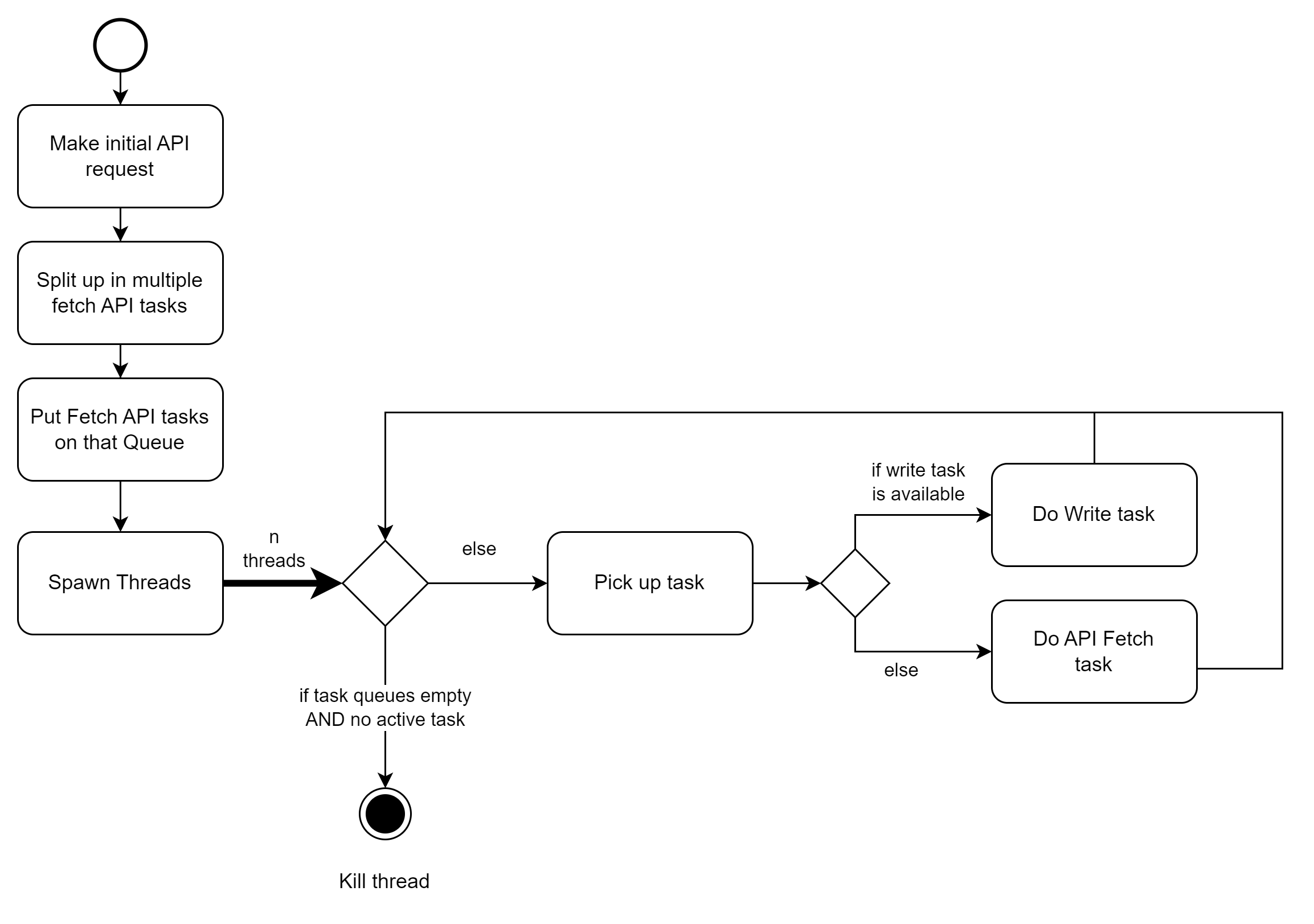
The first part of the process is doing an initial call to the API. In this call we will determine how we will split up the subsequent data fetch calls to obtain a single page. We define those single-page data fetch calls and put them on the Fetch API tasks queue. Then, the threads will spawn, and tasks can be picked up. The treads will prioritize picking up Writing tasks. This adheres to our choice for model B, i.e. writing the fetched data to disk as soon as possible.
When both queues are empty, the process is finished.
What happens inside both tasks is shown in the image below. This also includes some details on how we fine-tune interaction with the API.
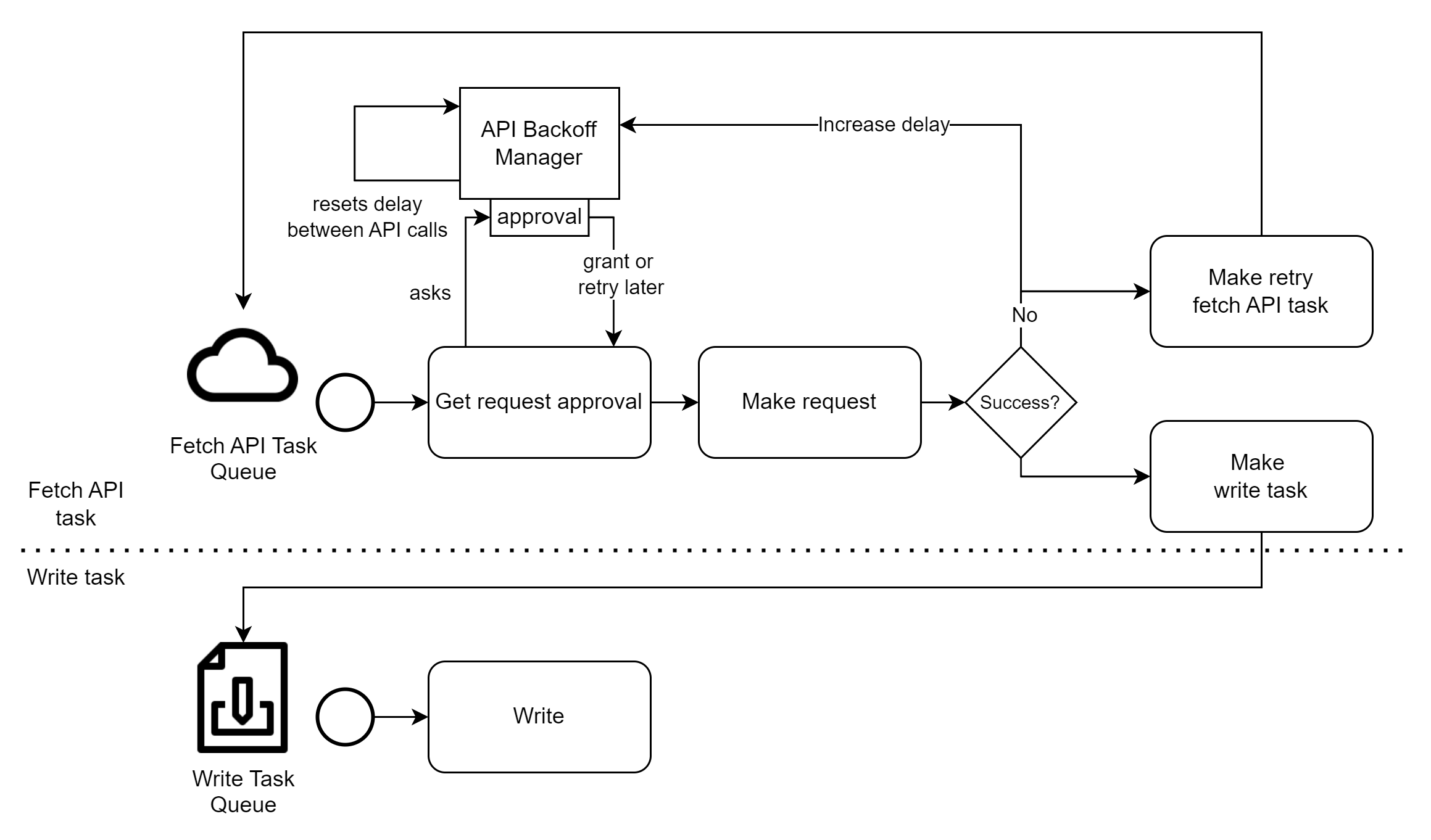
API request failures can lead to retries, based on how you configure it.
The API Backoff manager allows you to specify how gentle we need to be with sending requests to the API. You can set:
The delay between subsequent requests
The backoff factor with which delays should be increased upon request failure
The total amount of subsequent failures before we abort fetching any data from the API anymore
Decoupling Domain Logic from Control Logic
Above, I described the flow of the Control Logic. This follows a principle that could be reused for many workloads in which data needs to be fetched repetitively from an API. We didn't discuss yet the implementation of the Domain Logic.
The OperationModel class is an interface to design the operations that integrate with the above-described Control Flow. This is determined by the 'domain', i.e. the actual data loading question at hand.
It describes the following methods, which should be implemented by the user:
initial_operation: Performs the first API request, and should return a sequence containing all the arguments for requesting a single page during the multi-threading part.
fetch_from_api: Makes a single API request, based on the argument that is provided, and returns the request's response.
response_succeeded: Returns a boolean based on whether we assess that a response has succeeded or not.
upon_definitive_request_failure: An optional method that is used to handle the case of a single page not succeeding after the maximum number of retries. This can be used to write or log the details of the page that failed to be fetched.
upon_request_abortion: Similar to the method above. But this method will be invoked when the API is considered to be irresponsive, and the remaining fetch work is aborted.
write_fetched_data: Writes the data from a single page to disk.
An example that uses Spark to write to disk
The picture below shows how we can use multiple tables to not only write the fetched data but also keep track of the progress of loading historical data by fetching multiple pages separately.
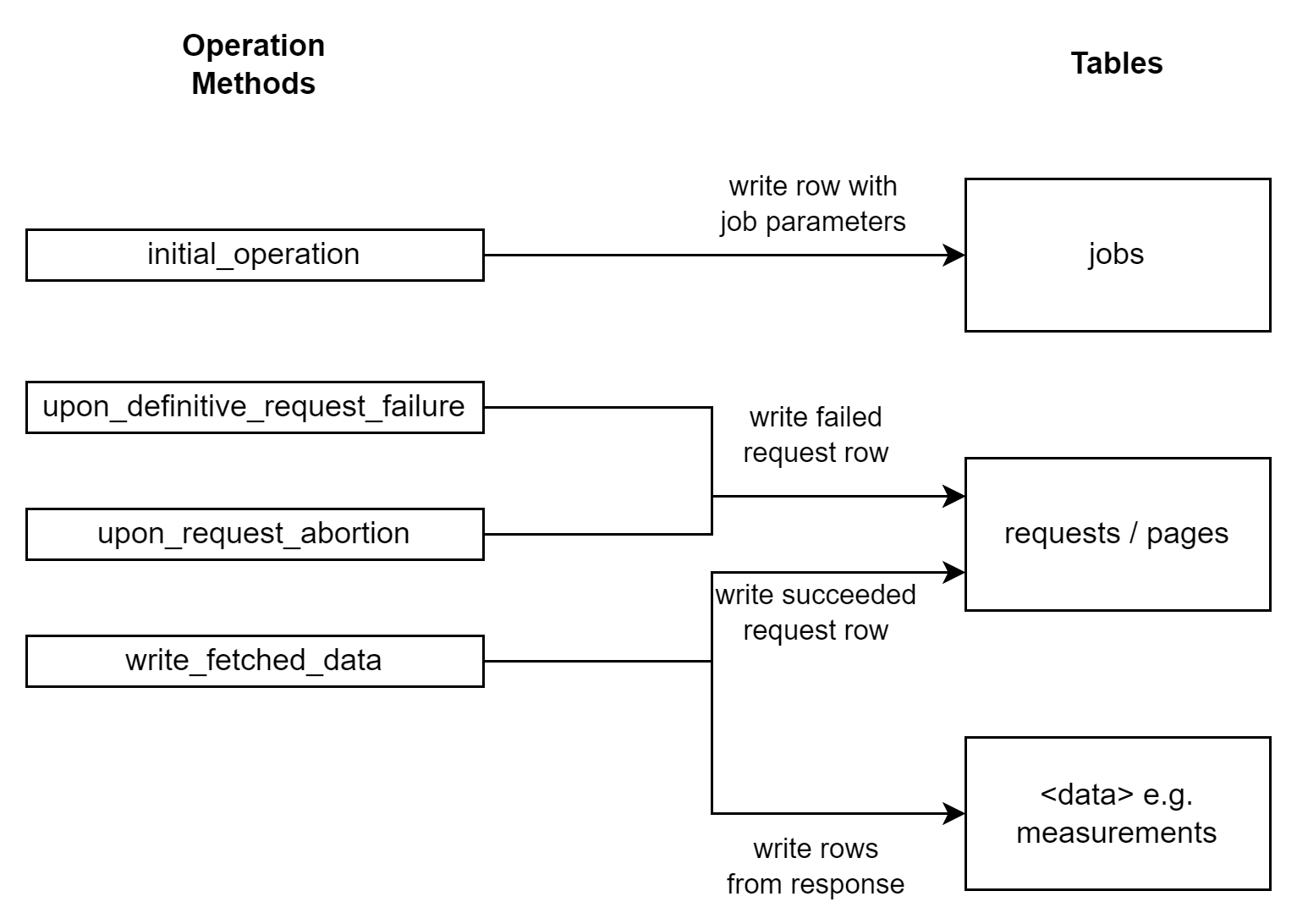
Keeping track of fetching data
The data table will contain all the fetched data from the API. However, the success of single requests can be tracked in the requests/pages table. This allows us to redo fetch work that hasn't succeeded, instead of redoing an entire job. The jobs table can be used to keep track of all the jobs that were initiated.
Spark can be your writer
Spark was used to write the data to tables, in the first use case to which I applied this framework. This works perfectly fine, as long as you use a single Spark Session, and keep the lifetime of a Spark dataframe that is written constrained to a single thread. So if you define the Spark DataFrame within one of the methods described above, and also write it there, you're good. Refrain from adding the DataFrame to anything outside the scope of that method, such as a global list for example.
Try it out locally
The repo also contains a demo simulation script. This script defines its own operations. It mocks the IO operations by doing some sleep time, and we randomly pick for each mocked API fetch operation whether it succeeded or failed. The extensive use of logs written to a local file allows you to inspect what actually happens when using the constructs from this library.
This blog post was written by a human. Not so much for the cover image :-)
