Use your own Python packages in Glue jobs
I am a software and data engineer focusing serverless data-intensive applications that are hosted on AWS.
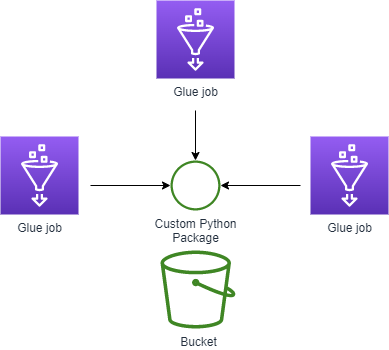
Many data engineering use cases require you to repeat some ETL logic on different (database) tables or event streams. It is advised to separate the ETL workflows for those tables in separate Glue jobs for multiple reasons:
- Keeping your ETL runs per table independent from each other
- Ease of debugging
- Independent tuning of infrastructure parameters depending on the load per table
- etc...
This poses the following problem: How to keep the ETL logic DRY, while using it in those separate Glue jobs simultaneously?
This can be achieved by defining your own Python package containing that logic, which is imported by the Glue jobs.
Create a Python Package
Poetry is a dependency management and packaging tool for Python. If you're coming from Javascript, you can see Poetry as some sort of Yarn for Python.
It allows you to very easily define a Python package by running poetry init or poetry new. Please refer to the docs for more detailed information.
Below I will share the steps I usually take to get started:
Create a Python Virtual environment
This is needed for testing, and utilizing the language features of your IDE.
Install Poetry in your system-wide or user-wide installation of Python. Note that is advised to use Python version 3.10 for Glue version 4.0, since that is the Python version that Glue actually uses. Using the same Python version for your package as the Python version of Glue will prevent any incompatibility problems.
Create the empty Python package:
poetry new <name of package>
Create a virtual environment. I usually put this in the directory of the new package:
repo/
├─ new_package/
│ ├─ .venv/
│ │ ├─ ...
│ ├─ new_package/
│ │ ├─ __init__.py
│ ├─ pyproject.toml
│ ├─ README.md
By using the command when in the top new_repo dir:
python3.10 -m venv .venv
The .venv is the name (and directory name) of the virtual environment that you will create.
Activate the virtual environment:
source .venv/bin/activate
Install Poetry into the virtual environment:
pip install poetry
Make sure that poetry is using the created venv by running poetry env info.
Now, add dependencies to your Python package with the Poetry CLI, start with Poetry itself: poetry add --group dev poetry
Note that poetry generates a lock file. Make sure that that lock file and the pyproject.toml file are checked-in in version control.
Build the package
To use the package, we need to build it into a wheel first. This is very easy using Poetry:
poetry build
It creates two files in the newly created dist folder. One of them is the wheel, which we will use in the subsequent steps.
Put the Wheel into an S3 bucket
Upload the wheel to an S3 bucket. Keep the name of the wheel exactly as it is, otherwise Pip cannot install the wheel. It can be placed into any (nested) directory in the S3 bucket.
Reference the Wheel in the Glue job
Refer the wheel in the Glue job parameters: Add the glue job argument key value pair with key --additional-python-modules and value <s3 uri to wheel>.
Also make sure that the Glue job has read access to the object in the S3 bucket.
Both these options can be achieved by using infrastructure-as-code. Check out this blog post for an example: martijn.sturm/defining-glue-etl-jobs-as-infrastructure-as-code
Test if it works
Import something from your Python package in the Glue job script, run the job, and see if it works! Now you can reuse the same logic in as many Glue jobs as you want.
I hope this blog post gave a good overview on how to use custom Python packages in Glue jobs. If you need any help in setting this up, please reach out to me.

